
Ami Baid
I'm a senior at UT Austin studying computer science and math as a Turing Scholar, and an undergraduate researcher in the UT Austin Computer Vision Lab advised by Professor Kristen Grauman.
I'm graduating in Spring 2026 and will be starting my Master's in CS at Stanford in the fall🌲
My research focuses on audio-visual multimodal learning. I'm excited about developing intelligent systems that can understand and reason over information from diverse modalities.
Research
My research centers on reliably leveraging audio in multimodal models while mitigating cross-modal interference.
Don't Let the Video Speak: Audio-Contrastive Preference Optimization for Audio-Visual Language Models
arXiv 2026 [paper] [project page]
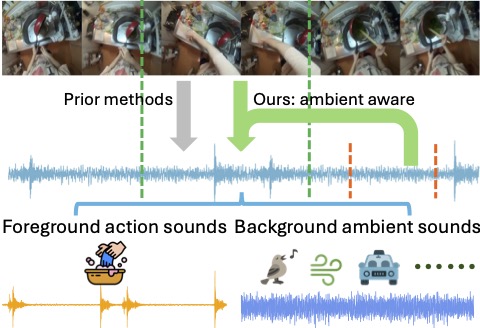
Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos
ECCV 2024, Oral [paper] [project page]
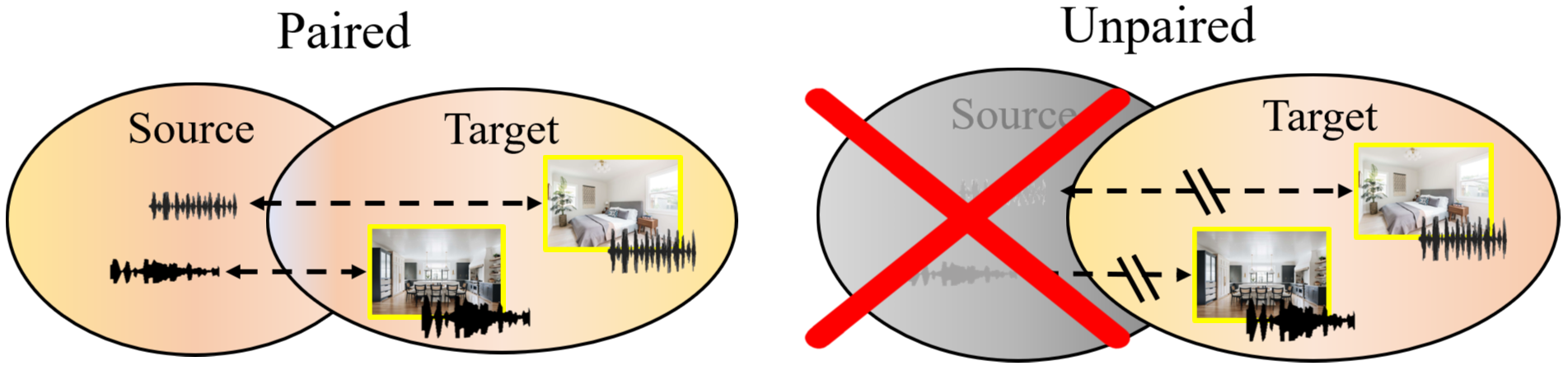
Self-Supervised Visual-Acoustic Matching
NeurIPS 2023 [paper] [project page]
Internships
- Engineering intern @ Stripe (summer 2025): extended Stripe's LLM-based compliance detection system to support image understanding on merchant websites.
- Software engineering intern @ Salesforce (summer 2024): automated a key workflow in Salesforce's internal Temporal platform and contributed to the open-source Terraform Temporal provider.
Other Projects
- Gaze-centered Egocentric Video Representations: built a gaze-aware preprocessing pipeline that reallocates resolution around gaze, improving efficiency in egocentric video QA. [GitHub]